The FDA had a meeting the last two days:
FDA is convening this two-day meeting to seek the Panel’s expert opinion and input on scientific issues concerning Direct to Consumer (DTC) genetic tests that make medical claims.
This meeting is focused specifically on issues regarding clinical genetic tests that are marketed directly to consumers (DTC clinical genetic tests), where a consumer can order tests and receive test results without the involvement of a clinician.
The American Medical Association of course wants to limit genetic testing so that you would need a doctor to supervise everything.
We urge the Panel to offer clear findings and recommendations that genetic testing, except under the most limited circumstances, should be carried out under the personal supervision of a qualified health care professional, and provide individuals interested in obtaining genetic testing access to qualified health care professionals for further information.
23andme had two presentations at the meeting which they have posted on their blog.
In our presentations, we take the position that all genetic testing services, whether ordered by a physician or offered through direct access, should adhere to the same standards. We simultaneously request that the FDA consider redefining and establishing regulatory standards, including some fundamental definitions, to accommodate large-scale genetic testing and support innovation of its technologies and applications. We also request that regulation be based upon evidence and not fear of potential harm to individuals which, to date, has not been demonstrated. In fact, growing numbers of participating individuals and independent studies focused on this issue provide preliminary evidence that the vast majority of people understand the information presented and experience no significant negative effects.
Genomics Law Report had an overview of the issues beforehand as well as a Twitter roundup of the meeting. Here are his thoughts after the first day:
First and foremost, I fully expect the MCGP (Molecular and Clinical Genetics Panel) to note, likely more than once, that given the complexity of the questions put to it by the FDA it should be afforded far more time to deliberate and research prior to making any recommendations.
If taking time out for further debate isn’t an option, what is the MCGP likely to recommend? Based on today’s deliberations, I think it’s a safe bet that the MCGP will advise the FDA to (1) demand clear proof of analytical and clinical validity for all genetic tests and (2) require that most, or perhaps even all, genetic tests with demonstrated or potential clinical significance be (to use the FDA’s terminology) “routed through a clinician.â€
In other words, I think the odds strongly favor an MCGP recommendation to the FDA that clinical (as defined by the FDA, which is itself a separate issue) direct-to-consumer genetic testing, when offered without a requirement that a clinician participate in the ordering, receipt and interpretation of the test, be removed from the marketplace. At least for the time being.
If you read my blog, you probably know my politics. I do however think that any regulations have to be shown to have actual tangible benefit and prevention of harm. Simple misinterpretation of genetic results by a regular joe causing hypothetical harm is not enough justification.
So what can you do? Razib Khan is already on the task.
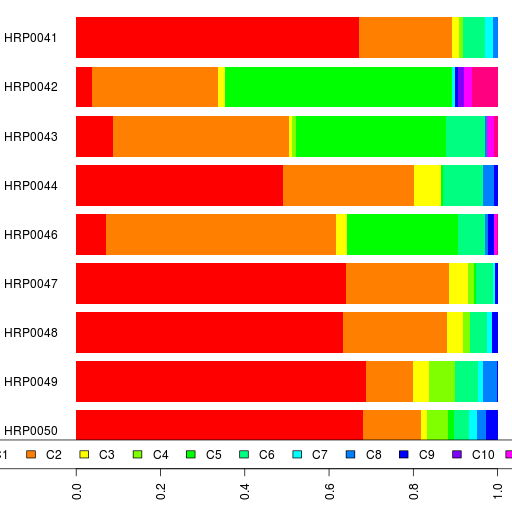
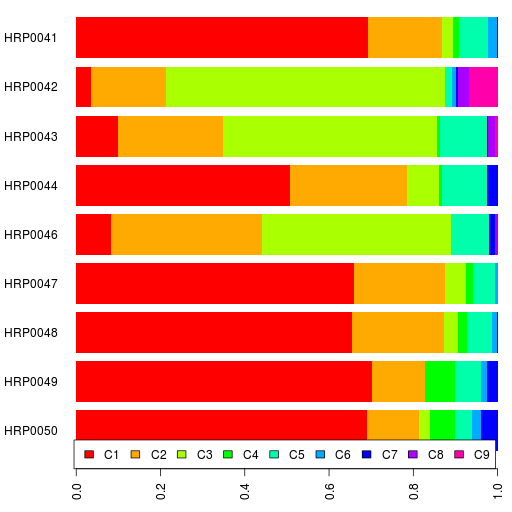
1) I am going to release my own 23andMe sequence into the public domain soon. I encourage everyone to download it. I would rather have someone off the street know my own genetic information than be made invisible by the government. That is my right. For now that right is not barred by law. I will exercise it.
2) Spread word of this video via social networking websites and twitter. The media needs to get the word out, but they only will if they know you care. Do you care? I hope you do. This is a power grab, this is not about safety or ethics. If it was, I assume that the “interpretative services†would be provided for free. I doubt they will be.
3) Contact your local representative in congress. I’ve never done this myself, but am going to draft a quick note. They need to be aware that people care, that this isn’t just a minor regulatory issue.
4) The online community needs to get organized. We’re not as powerful as a million doctors and a Leviathan government, but we have right on our side. They’re trying to take from us what is ours.
5) Plan B’s. We need to prepare for the worst. Which nations have the least onerous regulatory regimes? Is genomic tourism going to be necessary? How about DIYgenomics? The cost of the technology to genotype and sequence is going to crash. I know that the Los Angeles DIYbio group has a cheap cast-off sequencer. For those who can’t afford to go abroad soon we’ll be able to get access to our information in our homes. Let’s prepare for that day.
Here are the links to contact your House Representative and your Senators.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Recent Comments