Here are a couple of more maps of the South Asian admixture component from Simranjit incorporating the latest Harappa results.
")

He's posted more maps at his blog.
Here are a couple of more maps of the South Asian admixture component from Simranjit incorporating the latest Harappa results.
He's posted more maps at his blog.
Using the fifteen principal components shown before, I tried to use MClust to cluster the 573 individuals.
This time, I ran NNclean first to find out the outliers. NNClean pointed to the following as outliers:
HGDP00104 HGDP00100 HGDP00119 HGDP00112 HGDP00118 HGDP00279 HGDP00060 HGDP00029 HGDP00076 HGDP00041 HGDP00146 HGDP00163 HGDP00234 HGDP00412 HGDP00090 HGDP00148 HGDP00165 HGDP00068 HGDP00134 HGDP00149 HGDP00052 HGDP00074 HGDP00098 HGDP00153 HGDP00173 HGDP00376 HGDP00143 HGDP00158 HGDP00145 HGDP00161 HGDP00151 HGDP00243 HGDP00139 HGDP00140 HGDP00177 HGDP00224 GSM536497 GSM536806 GSM536807 GSM536808 I16 I3 I5 SS231506 HRP0001
As you can see, I am included in this list.
Then I used this list of outliers to initialize "noise" in the MClust procedure. The final list of outliers is as fllows:
HGDP00279 HGDP00029 HGDP00134 HGDP00151 GSM536806 GSM536807 GSM536808
These are 1 Kalash, 1 Brahui, 2 Makranis, and 3 Paniyas.
There are a bunch of interesting things in the results. For example, Pathans and Punjabis were mostly indistinguishable by this technique. But let me leave you with a caution: Some of these clusters are nice, tight ones and others are loose, long ones, so don't overread the results.
I ran PCA on the South Asian populations included in Reference II dataset as well as 38 South Asian participants of Harappa Project. This is sort of a complementary analysis to the Ref1 South Asian one, as this one includes Kalash, Hazara and the additional South Asian groups in Xing et al.
The reference populations included are: Andhra Brahmin, Andhra Madiga, Andhra Mala, Balochi, Bnei Menashe Jews, Brahui, Burusho, Cochin Jews, Gujaratis, Gujaratis-B, Hazara, Irula, Kalash, Makrani, Malayan, Nepalese, North Kannadi, Paniya, Pathan, Punjabi Arain, Sakilli, Sindhi, Singapore Indians, Tamil Nadu Brahmin, and Tamil Nadu Dalit.
Here's the spreadsheet showing the eigenvalues and the first 15 principal components for each sample.
I computed the PCA using Eigensoft which removed 13 samples as outliers. The Tracy-Widom statistics show that about 25 eigenvectors are significant.
Here are the first 15 eigenvalues:
| 1 | 6.374483 |
| 2 | 3.650626 |
| 3 | 3.270121 |
| 4 | 2.999767 |
| 5 | 1.937818 |
| 6 | 1.713315 |
| 7 | 1.538295 |
| 8 | 1.503051 |
| 9 | 1.458331 |
| 10 | 1.448079 |
| 11 | 1.433288 |
| 12 | 1.414678 |
| 13 | 1.408943 |
| 14 | 1.390791 |
| 15 | 1.38101 |
Here is a 3-D PCA plot (hat tip: Doug McDonald) showing the first three eigenvectors. The plot is rotating about the 1st eigenvector which is vertical. Also, I have stretched the principal components based on the corresponding eigenvalues. Also, you can highlight the individual project participants in the plot by using the dropdown list below the plot.
Now here are plots of the first 14 eigenvectors. In this case, I have not stretched the principal components, so keep in mind that the first eigenvector explains 1.75 times variation compared to the 2nd eigenvector.







I got my daughter a netbook, so now my computer is doing Harappa Project work 24x7.
Also, Simranjit was nice enough to offer me the use of a server. For privacy reasons, I am not going to upload any of the participants' data there but it is much faster than my machine and hence very useful for running Admixture on the reference data (especially with crossvalidation).
As for steps back, I downloaded the current 1000genomes data (1,212 samples, 2.4 million SNPs). It's in vcf format. Using vcftools to convert it to ped format will take about 3 weeks. Yes you heard that right. BTW, the good stuff from a South Asian point of view will come later this year with a 100 Assamese Ahom, 100 Kayadtha from Calcutta, 100 Reddys from Hyderabad, 100 Maratha from Bombay and 100 Lahori Punjabis.
Also, I spent most of Sunday evening and night in the ER and got a diagnosis of ureterolithiasis for my efforts. All I can say is: Three cheers for Percocet!!
UPDATE: Dienekes was kind enough to send me his conversion code which looking at the source code should run really fast.
I am still astonished at why the vcftools conversion code is so slow. May be I should look at their source code.
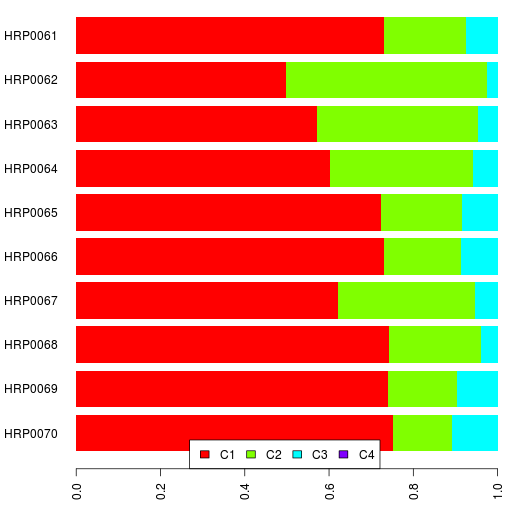
Here are their ethnic backgrounds and the results spreadsheet. Also relevant are the reference I admixture results.
If you can't see the interactive bar chart above, here's a static image.
I dare you to generalize!
PS. This was run using Admixture version 1.04.
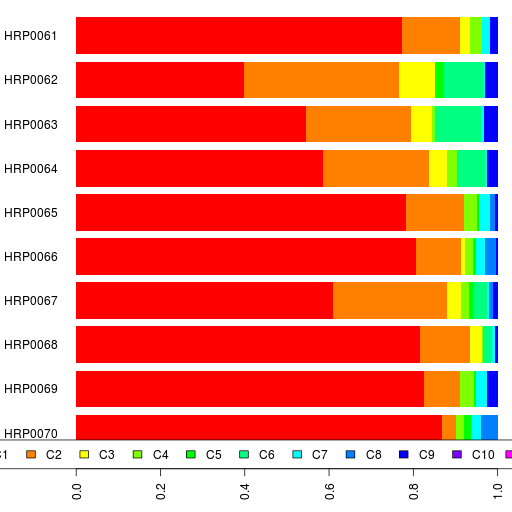
Here are their ethnic backgrounds and the results spreadsheet. Also relevant are the reference I admixture results.
The interesting samples here are the Gujarati and the Punjabi. HRP0064 is very different from the other Punjabis so far.
If you can't see the interactive bar chart above, here's a static image.
PS. This was run using Admixture version 1.04.
I have a total of 67 participants in the project right now who have sent me their raw data. This is not counting those who have relatives participating and thus have to be filtered out for most analysis other than individual admixture percentages etc where I divide participants into small groups.http://polvam.ru
The following groups are represented:
I need to post analyses of Tamils, Bengalis and Punjabis soon.
I ran PCA on the Reference II dataset which includes 3.161 samples from various populations but with only 23,000 SNPs in common.
Here are the top ten eigenvalues:
While the first two eigenvalues are much bigger than the rest, the first explains 7.12% of the variation and the second 4.77%, the Tracy-Widom stats show that about 54 eigenvectors are significant.
Here are the plots for the first 10 principal components. Remember that the 1st eigenvector is 1.5 times the 2nd.





Here is a 3-D PCA plot (hat tip: Doug McDonald) showing the first three eigenvectors. The plot is rotating about the 1st eigenvector which is vertical. Also, I have stretched the principal components based on the corresponding eigenvalues.
I also ran MClust on the PCA data and got 17 clusters. The results are in a spreadsheet. I am sure with more principal components than the 10 I used, I would be able to deduce finer population structure.
Do take a look at the clusters assigned to the South Asian populations from Xing et al.
From the Reference I K=17 Admixture results, Simranjit has created more isopleth maps.
Mediterranean component:

Southwest Asian component:

While my computer's busy running K=12 admixture on batch 7, K=17 admixture on batch 1, some MClust experiments and converting 1000genomes data from vcf to ped and I am reeling from the pollen count (3,939 yesterday), here are some links to my personal genetics blogging.
For the record, my daughter complains about all the "Trantor windows" open on the computer all the time. She calls the terminal windows "Trantor" because of the shell prompt. My desktop is named Trantor. Now who can guess what my laptop, my other desktop and my wireless network are named?

{kind=link}
{kind=link}
Recent Comments