Genetic Affinities of the Central Indian Tribal Populations by Gunjan Sharma, Rakesh Tamang, Ruchira Chaudhary, Vipin Kumar Singh, Anish M. Shah, Sharath Anugula, Deepa Selvi Rani, Alla G. Reddy, Muthukrishnan Eaaswarkhanth, Gyaneshwer Chaubey, Lalji Singh, Kumarasamy Thangaraj:
Background
The central Indian state Madhya Pradesh is often called as ‘heart of India’ and has always been an important region functioning as a trinexus belt for three major language families (Indo-European, Dravidian and Austroasiatic). There are less detailed genetic studies on the populations inhabited in this region. Therefore, this study is an attempt for extensive characterization of genetic ancestries of three tribal populations, namely; Bharia, Bhil and Sahariya, inhabiting this region using haploid and diploid DNA markers.Methodology/Principal Findings
Mitochondrial DNA analysis showed high diversity, including some of the older sublineages of M haplogroup and prominent R lineages in all the three tribes. Y-chromosomal biallelic markers revealed high frequency of Austroasiatic-specific M95-O2a haplogroup in Bharia and Sahariya, M82-H1a in Bhil and M17-R1a in Bhil and Sahariya. The results obtained by haploid as well as diploid genetic markers revealed strong genetic affinity of Bharia (a Dravidian speaking tribe) with the Austroasiatic (Munda) group. The gene flow from Austroasiatic group is further confirmed by their Y-STRs haplotype sharing analysis, where we determined their founder haplotype from the North Munda speaking tribe, while, autosomal analysis was largely in concordant with the haploid DNA results.Conclusions/Significance
Bhil exhibited largely Indo-European specific ancestry, while Sahariya and Bharia showed admixed genetic package of Indo-European and Austroasiatic populations. Hence, in a landscape like India, linguistic label doesn't unequivocally follow the genetic footprints.
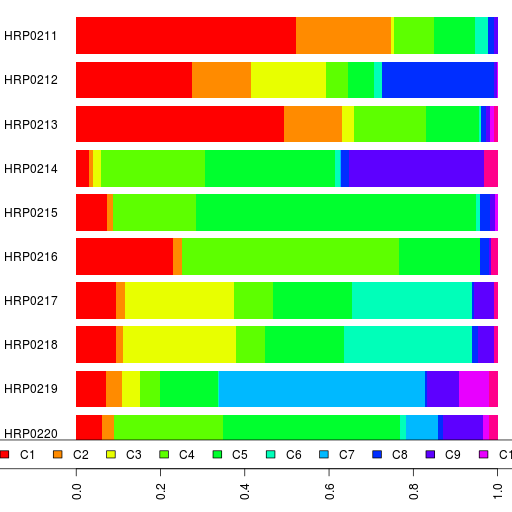
Did they seriously use only 48 AIMs (ancestrally informative markers) for their autosomal analysis?
UPDATE: Here is their autosomal analysis using STRUCTURE on 48 AIMs.
Can't say I am impressed. It is very noisy. They have the African component varying from 6.2% to 13.2% in populations that should have none. They also have Bhil at 10.8% East Asian (I got 0%), Sahariya at 15.8% (me at 12%), and Gond at 9.2% (I got 7%).
In short, using 48 AIMs instead of 118,000 SNPs leads to really noisy results.



















{kind=link}
{kind=link}
Recent Comments