Since the version 1.1 of Admixture with supervised option came almost two months ago, I have been salivating over it.
My original use case for it is not possible (for now). I wanted to be able to assign a few of the K ancestral components to specific reference populations and let the other ancestral components fall where they may. But we can do supervised admixture only by assigning all K ancestral components.
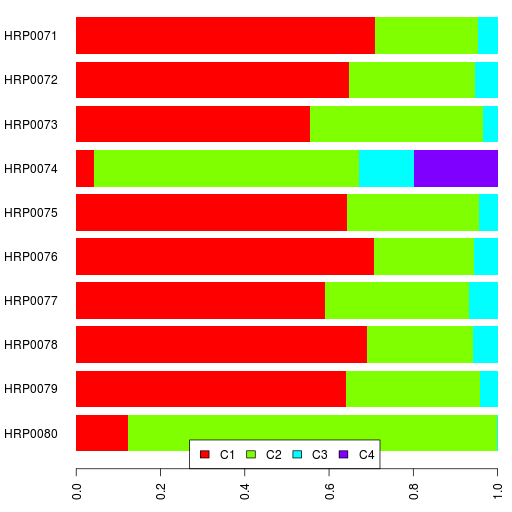
So I decided to test this supervised option by mimicking the three continental percentages 23andme assigns you on their ancestry painting page. Mine are:
| Europe |
91.22% |
| Asia |
8.69% |
| Africa |
0.09% |
You can get the extra precision (and false sense of accuracy) here.
Regarding the reference populations used for ancestry painting, 23andme says:
23andMe takes advantage of publicly available data for four populations studied extensively via the International HapMap project (hapmap.org). That project obtained the genotypes for 60 individuals of western European descent from Utah, 60 western African individuals from Nigeria, and 90 eastern Asian individuals, 45 from each of Japan and China. Because the two eastern Asian populations are geographically near one another and relatively similar at the genetic level, 23andMe combines these to form a single eastern Asian reference population.
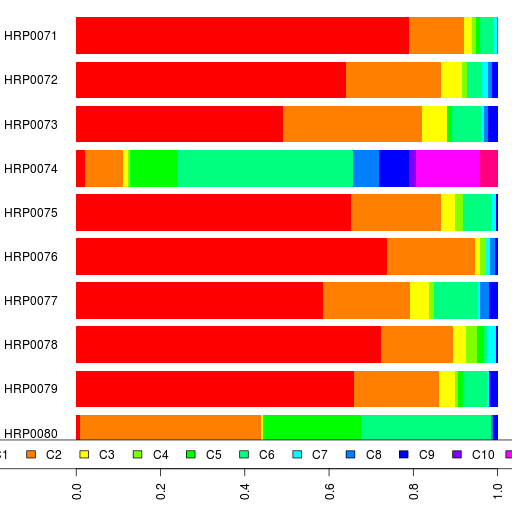
So I dug up my reference admixture run at K=3 and found the same number of samples of these HapMap populations by looking for those samples which had the highest percentage in the respective component.
Then I combined these 210 samples from the HapMap with 74 Harappa Project participants (HRP0001 to HRP0079, excluding 5 who are related to others).
The results of the supervised admixture run are in a spreadsheet and also shown in a bar chart below.
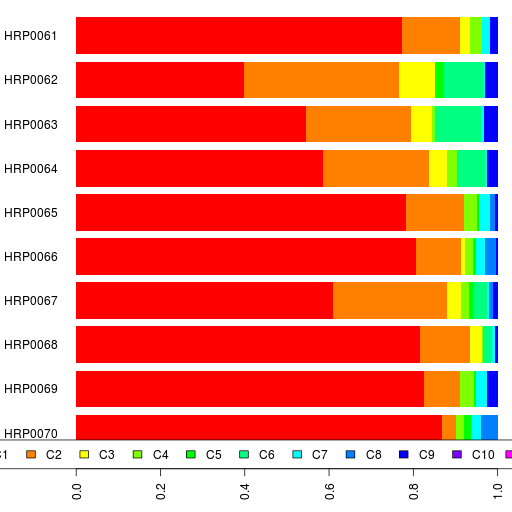
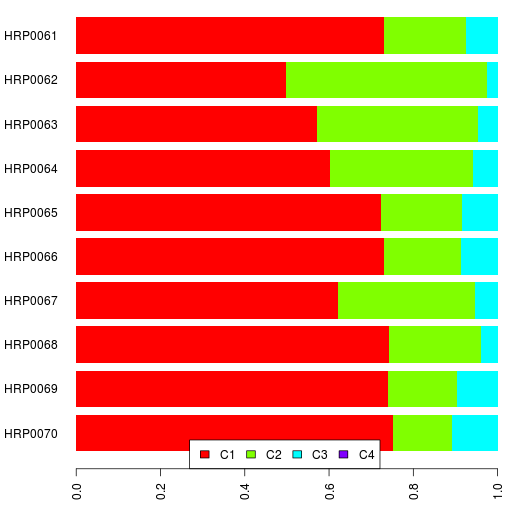
Since I did run an unsupervised K=3 admixture analysis of the first Harappa batch with the whole reference I populations, you can compare these results to those.





")





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Recent Comments