To my standard reference 3 (list of populations), I added the Yunusbayev et al Caucasus samples which include the following:
- 20 abhkasians
- 16 armenians
- 19 balkars
- 13 bulgarians
- 20 chechens
- 14 kumyks
- 6 kurds
- 15 mordovians
- 16 nogais
- 15 north-ossetians
- 15 tajiks
- 15 turkmens
- 20 ukranians
These 204 samples increased the total to 4,090.
Then I applied a stricter IBD relationship cutoff than I have before. Previously my focus was on removing relatives, but now I wanted to remove samples that seemed highly inbred or belonged to highly bottle-necked small groups so they would not create their own clusters in Admixture. This process removed the following 164 samples:
- maasai 30
- papuan 15
- karitiana 12
- pima 12
- onge 8
- surui 7
- luhya 6
- melanesian 6
- colombian 5
- hadza 5
- koryaks 5
- sandawe 5
- san 4
- turkmens 4
- african-americans 3
- east-greenlanders 3
- great-andamanese 3
- nganassans 3
- chenchu 2
- evenkis 2
- han-chinese-south 2
- maya 2
- mbutipygmy 2
- mexicans 2
- utahn-whites 2
- aus 1
- bantukenya 1
- british 1
- chinese-americans 1
- gujaratis-b 1
- iranians 1
- naxi 1
- north-kannadi 1
- samaritians 1
- she 1
- tuvinians 1
- yemenese 1
- yoruba 1
- yukaghirs 1
Finally, I added the 165 founders from the Harappa Project participants (up to HRP0180).
The crossvalidation error for the admixture results with K (number of ancestral components) from 2 to 20 is plotted here.

Zooming in,

The lowest crossvalidation errors are for K=17 and K=12.
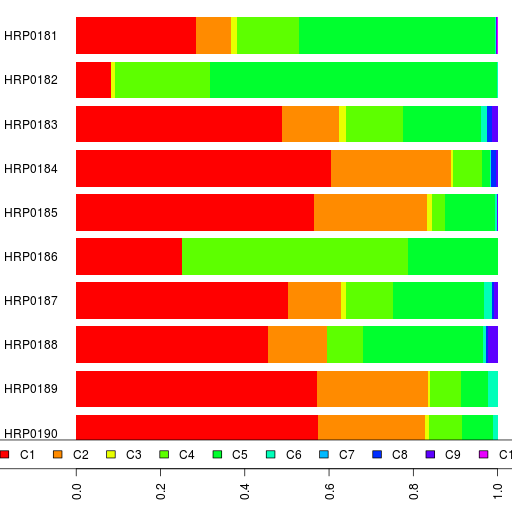
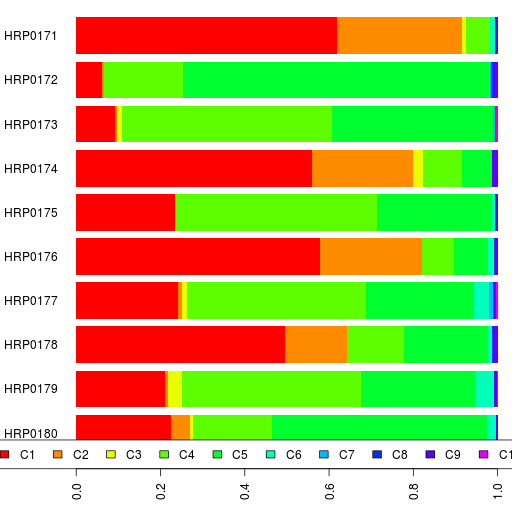
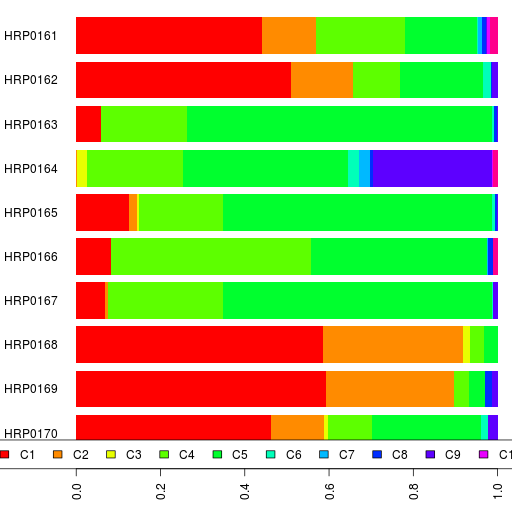
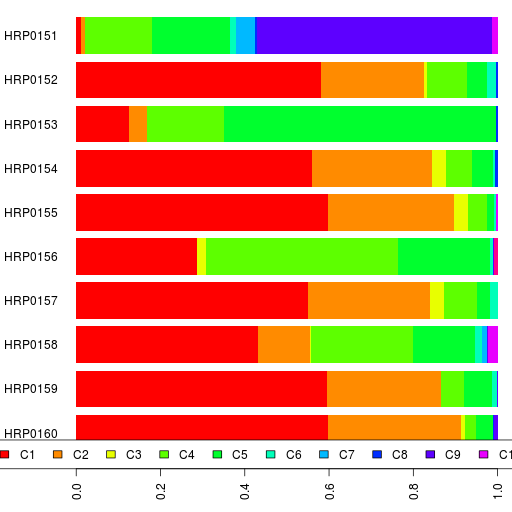
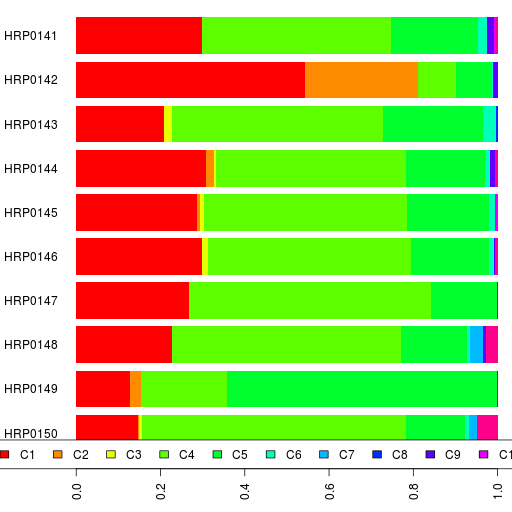
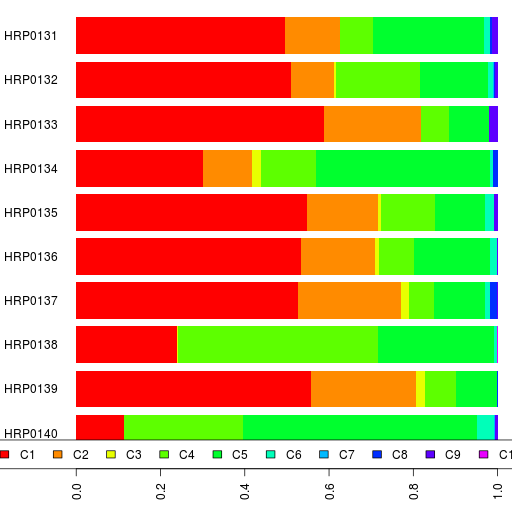
The admixture results are in a spreadsheet.
In addition to K=17 and K=12, take a look at the results for K=15.
PS. I should point out that the names for the ancestral components are just useful mnemonics based on the current distribution of that component. Also, a component with the same name at one value of K is different from a similarly named component at another K.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Recent Comments