Now I am going nuts on this dataset consisting of South Asians (minus Kalash and Hazara) from Reference I and some Harappa participants, but I promise this is the last item on this specific data. I will however do similar analyses some time after integrating all the new South Asian samples I have gotten (via project participation as well as from research data).
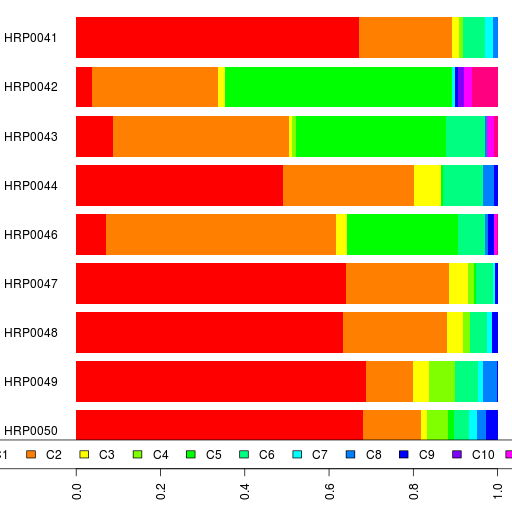
I ran MDS on the data in Plink and then retaining various number of MDS dimensions, ran MClust on it. This is what Dienekes calls Clusters Galore.
Here are the plots of the MDS, two dimensions at a time.




The graph of number of MDS dimensions retained versus optimum number of clusters computed by Mclust is as follows:

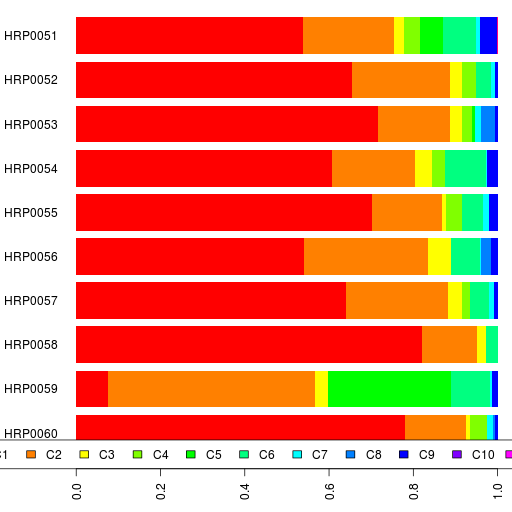
The maximum number of clusters (28) are inferred with 8 MDS dimensions. So I posted the clustering results for 8 MDS dimensions + 28 clusters.
Some observations on the clusters:
- 56 of the 62 Gujaratis are in cluster CL1 and the remaining 6 are in CL5. Both are Gujarati-only clusters. Let's see where the Harappa Gujaratis fall next time I do this analysis,
- CL2 has an Andhra Reddy, Caribbean Indians, a Keralan, a few Gujaratis-B, and a third of the Singapore Indians.
- Gujaratis-B are a varied lot spread out into CL3, CL7, CL2, CL8, CL4, CL6, and CL15, but half are in CL3.
- CL6 has a lot of the South Indian Brahmins
- Burusho are isolated
- Punjabis from the project seem to be divided among CL7, CL8 and CL15.
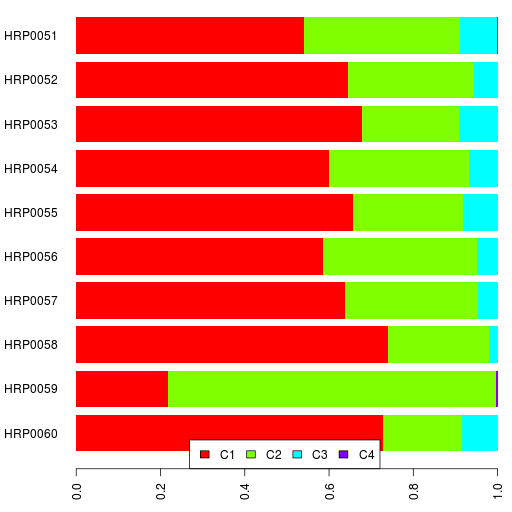
I also posted the results for 20 MDS dimensions resulting in 21 clusters.






{kind=link}
{kind=link}
{kind=link}
Recent Comments