Razib pointed out the paper "Population Genetic Structure in Indian Austroasiatic speakers: The Role of Landscape Barriers and Sex-specific Admixture" by Gyaneshwer Chaubey, Mait Metspalu, Ying Choi, Reedik Mägi, Irene Gallego Romero, Pedro Soares, Mannis van Oven, Doron M. Behar, Siiri Rootsi, Georgi Hudjashov, Chandana Basu Mallick, Monika Karmin, Mari Nelis, Jüri Parik, Alla Goverdhana Reddy, Ene Metspalu, George van Driem, Yali Xue, Chris Tyler-Smith, Kumarasamy Thangaraj, Lalji Singh, Maido Remm, Martin B. Richards, Marta Mirazon Lahr, Manfred Kayser, Richard Villems and Toomas Kivisild to me 36 hours ago. And I have their dataset now.
I have been told that the data will hopefully be in the NCBI GEO database soon.
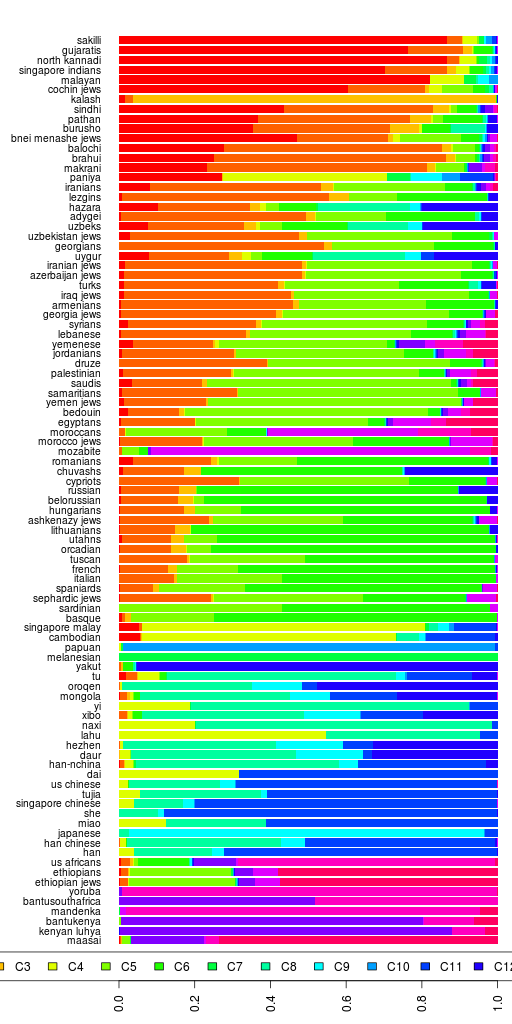
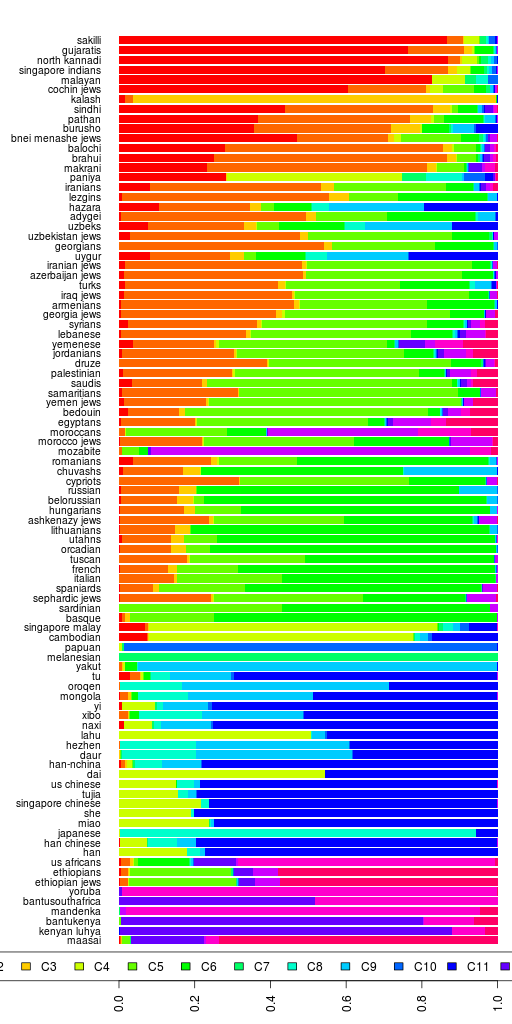
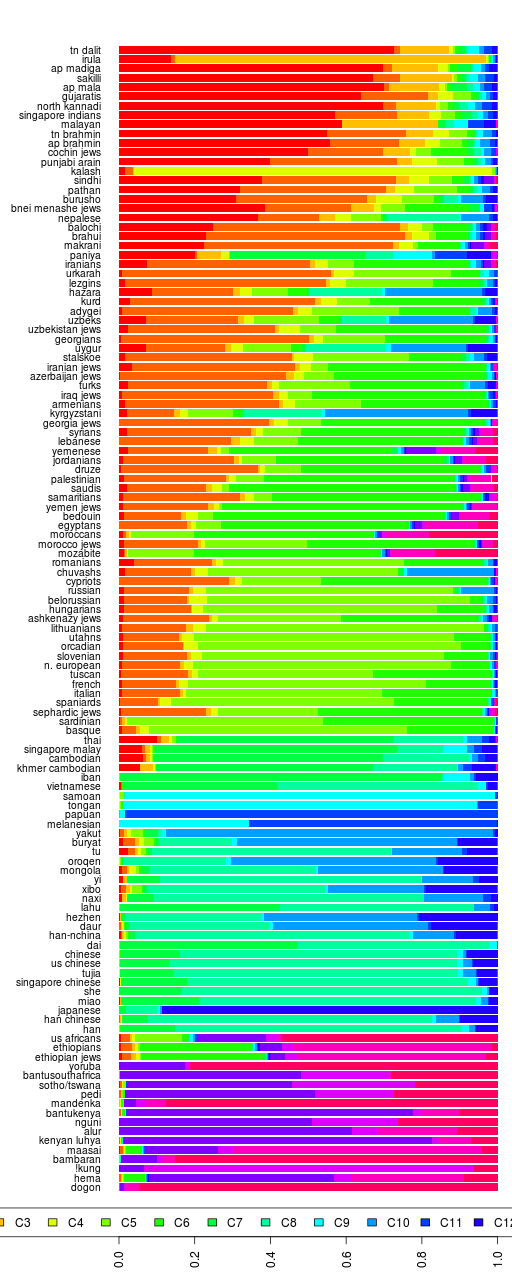
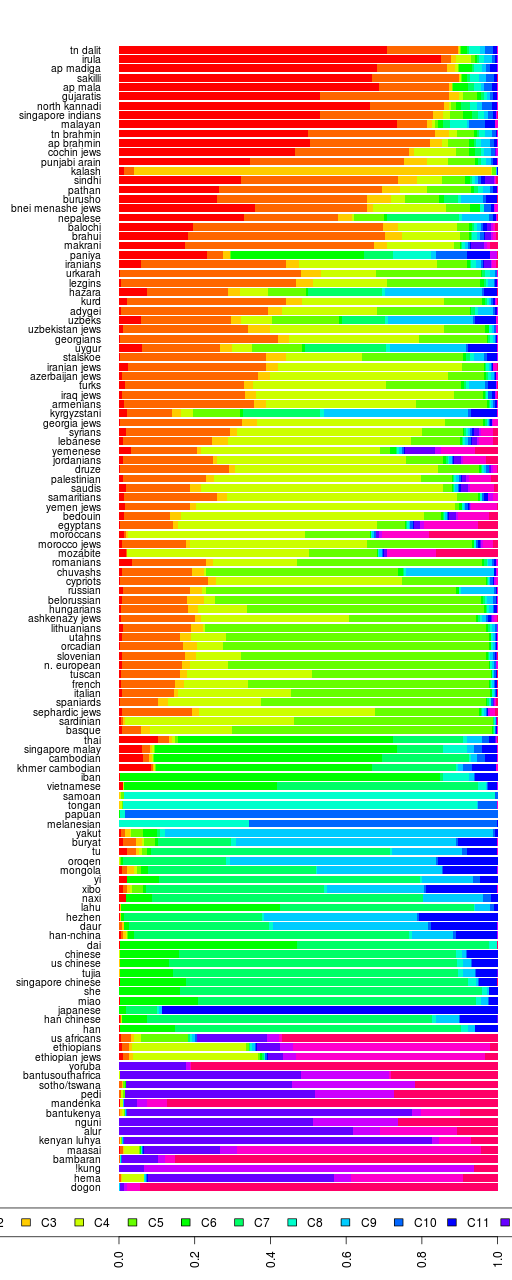
There are a total of 41 samples with 527,319 SNPs in the data. There are Bonda, Savara, Juang and Gadaba from Orissa; Santhal and Asur from Jharkand; Kharia from Chattishgarh; Ho from Bihar; Khasi and Garo from Meghalaya; and some (15) Burmese.
PS. I have created a separate page for references where I link to the papers which led to the datasets I am using.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Recent Comments