Handschar created a dendrogram using a hierarchical classifier based on K=12 admixture results and wondered:
When I run a classification based on simple euclidean distances (not a phylogeny), the Armenians and Turks, as they were, prior to the removal of the four North European admixed Behar samples in David's runs, cluster together. The North European component, in Dodecad Armenians, is practically nonexistent. I am not sure how the Harappa project "European" component translates to Dodecad components. If the admixed Armenians are included, it is possible their inclusion is impacting the Armenian population component percentages. Then again, even if included, perhaps your runs are picking up on something not previously detected. The Armenians, in previous classification runs, ordinarily matched one or more of the Caucasian Jewish groups.
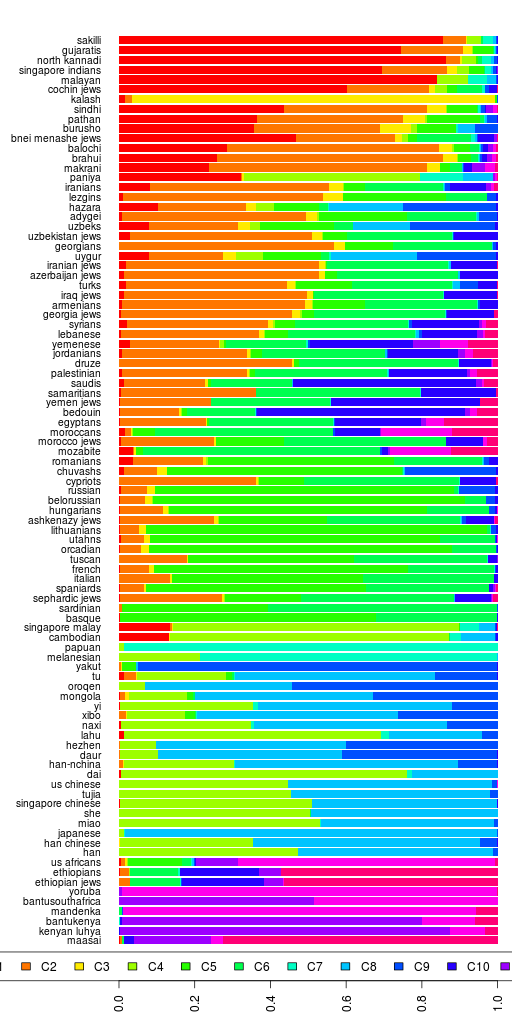
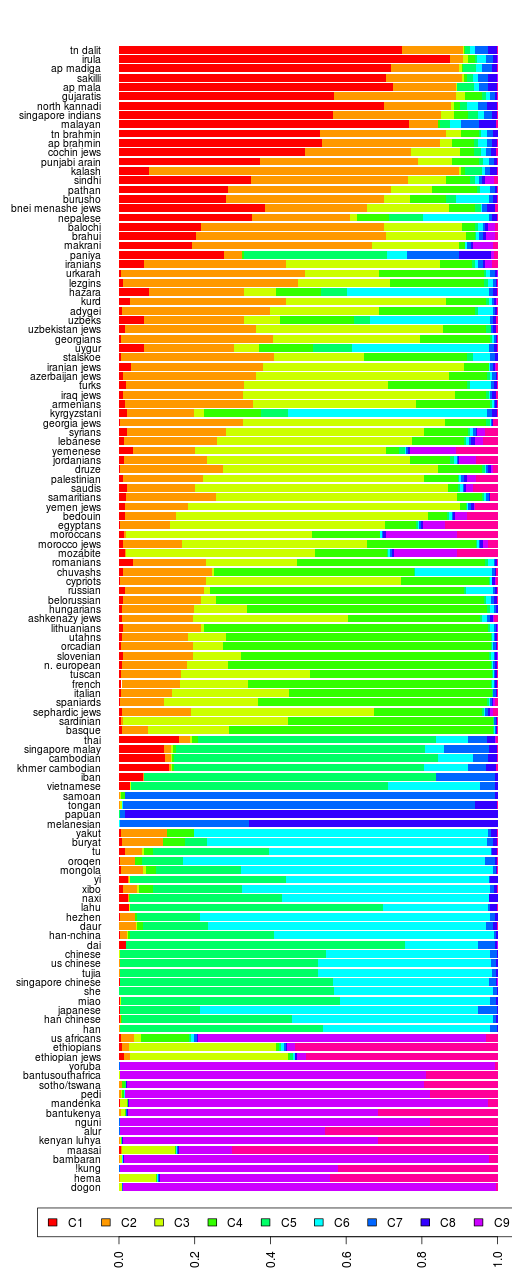
While looking into his question, I figured that I would create some dendrograms too. The ones here are based on the K=12 admixture results of Reference I dataset (spreadsheet). Also, I am using the pairwise Euclidean distance of the Admixture results between population groups to do a complete linkage hierarchical classification. So these dendrograms show which groups are closest in terms of their admixture percentages and do not show shared ancestry. In other words, it is not a phylogeny or a family tree.
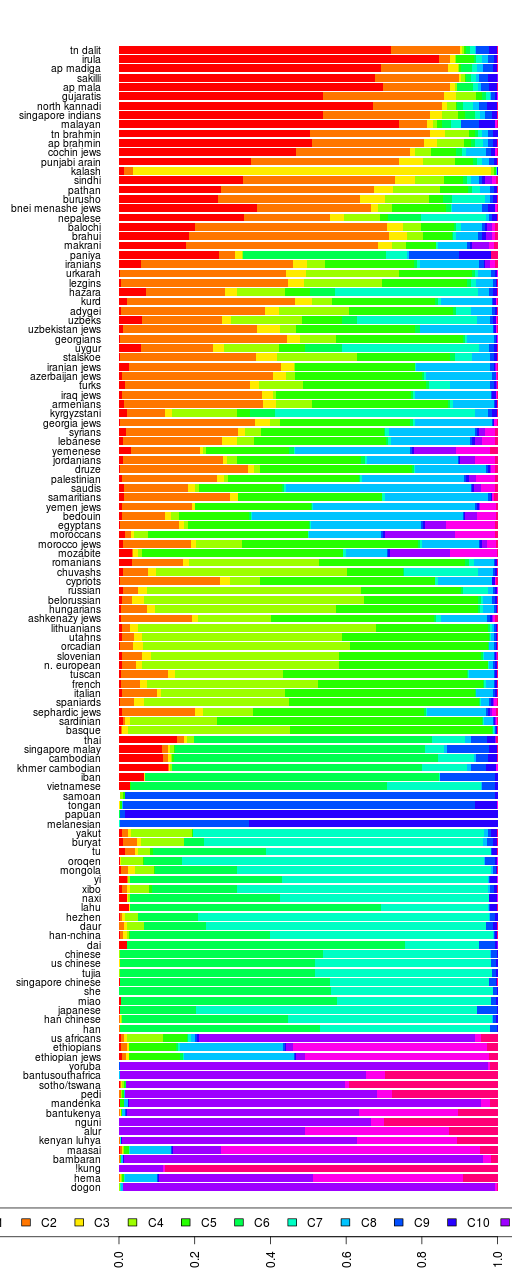
First, I used the mean admixture percentages for each group, as given in the spreadsheet.

Reference 1 Mean Admixture Complete Linkage Dendrogram
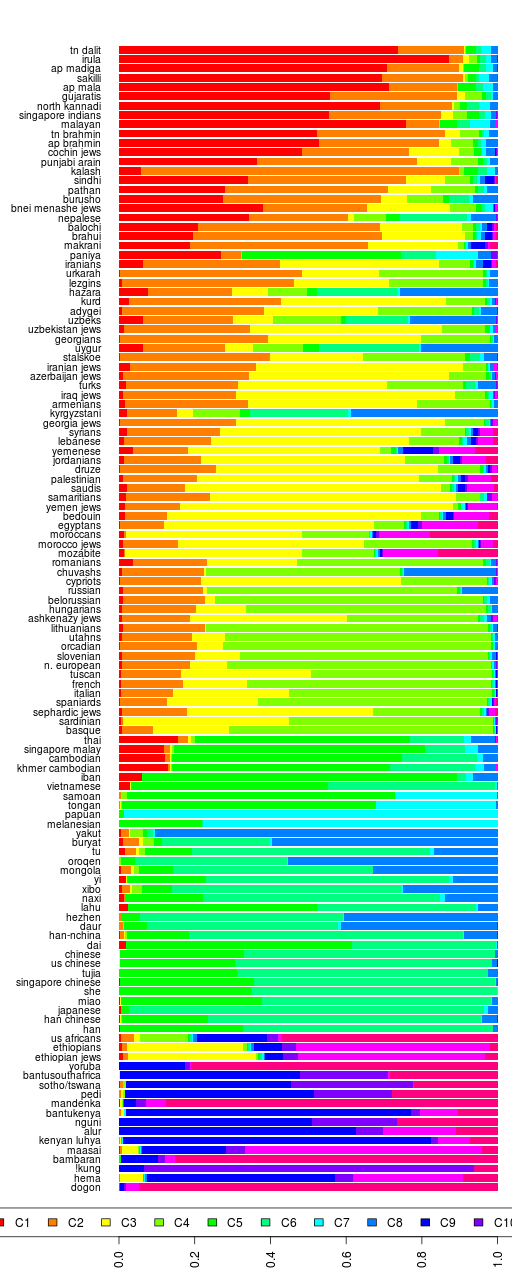
There are a number of outliers in the dataset. For example, some Arabs and Sindhis with African admixture, some Armenians with a lot more European component than the rest, etc. Therefore, I thought a better approach would be to do the same classification using the median admixture percentages for each population group.

Reference 1 Median Admixture Complete Linkage Dendrogram
Using the median sample from each population, handschar was correct that the Armenians match the Caucasian Jewish groups.
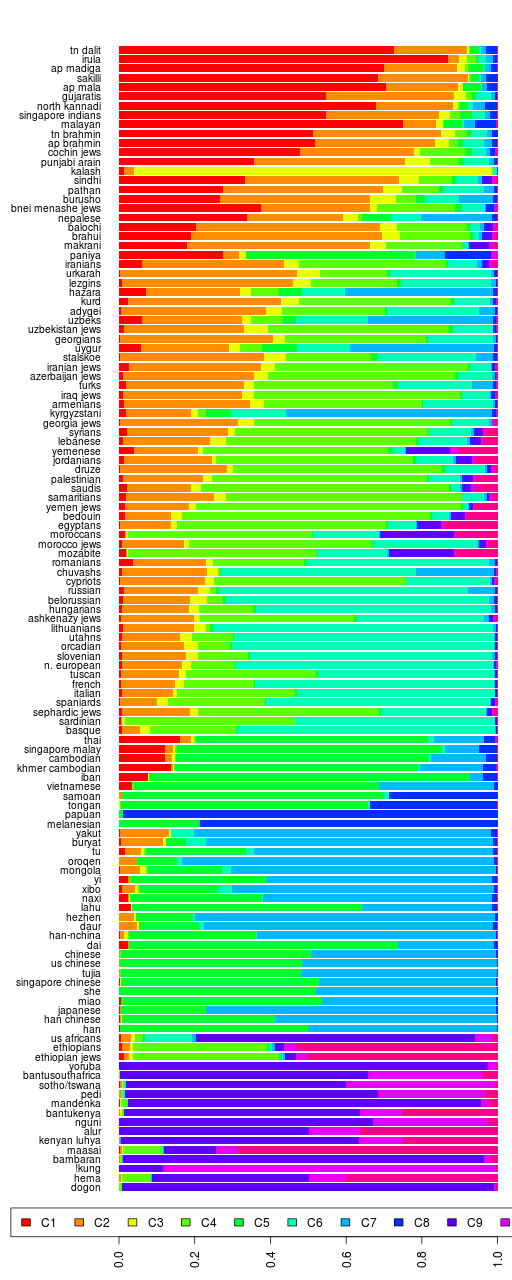
UPDATE: Here's another dendrogram in which I take the mean of the ancestral components for each population after removing outliers.
 Admixture Complete Linkage Dendrogram")
Reference 1 Mean (No Outliers) Admixture Complete Linkage Dendrogram
Again, don't take these dendrograms to heart. All they show is the distance between the admixture results of different populations.










 Admixture Complete Linkage Dendrogram")

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Recent Comments